You don't always need the best model. You need the right one.
A few weeks ago, Tim was running through his entire AI usage budget in under thirty minutes. He was just running the Learn & Grow Agent, an internal tool Nimble built to automatically evaluate conversations from AI agents. It scores each conversation across five criteria: correctness, empathy, frustration level, and a couple more. Then it digs into why a conversation scored low. Was it the prompt? The knowledge base? The code? … and suggests concrete fixes.
Good idea, expensive to run.
Every evaluation triggers multiple LLM calls. Stack enough of those together and your usage bill climbs fast. He needed a way to keep those costs down without tanking quality.
The solution: stop sending everything to the cloud. Run it locally instead. 🤯
What "running locally" actually means
You download a model and run it on your own machine. No API calls. No per-token billing. The only real costs are electricity and storage.
The tool that makes this easy is Ollama, a small server you run on your PC that lets you pull and run open-source models like you'd install any other app. The library is huge: DeepSeek, Gemma, Qwen, Mistral, and dozens more, each in multiple sizes.
Smaller models (2B parameters) are faster but know less. Bigger ones (31B, what Tim's running on 48GB RAM) are slower but more capable. None of them come close to a frontier cloud model in raw knowledge, but for reasoning tasks like evaluating a conversation against a rubric, the gap is smaller than you'd think.
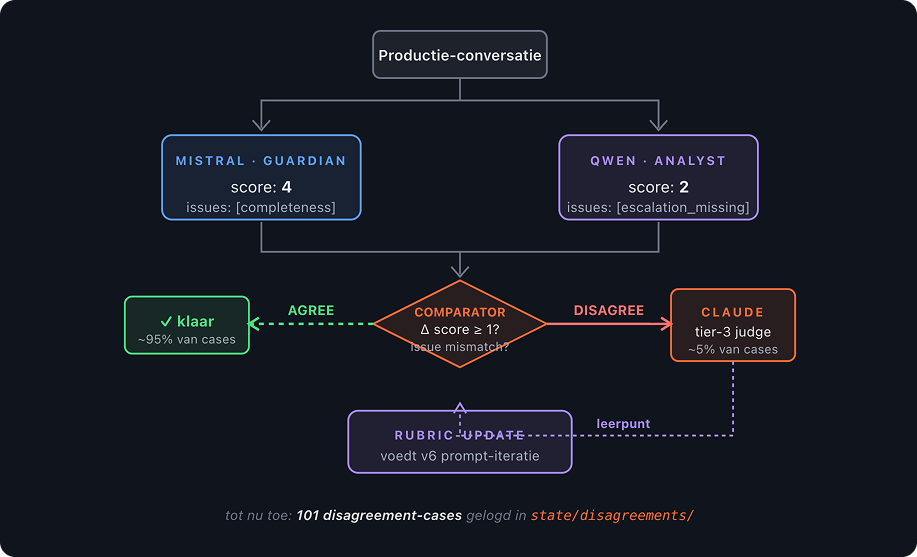
The three-tier setup
Rather than picking one model and committing, he built a routing system:
Tier 1 → Mistral (fast, small): Every conversation gets evaluated here first. If the score looks clean and confident, that's it. Done. No further calls needed.
Tier 2 → Qwen3 (deeper reasoning): If Mistral's output looks uncertain or the score seems off, Qwen3 runs a fresh evaluation independently. Then the system compares the two. If they're roughly aligned, move on.
Tier 3 → Cloud API (edge cases only): If Tier 1 and Tier 2 disagree significantly, then it goes to the cloud. For real scrutiny of a genuinely tricky case.
The result: about 95% of evaluations never leave the machine. Cloud calls are reserved for the 5% that actually need them. Token costs dropped by 70%. Score!

Why these models specifically
Mistral was chosen because it natively supports Dutch, French, and English the three languages Kailo (Combell) works in. That matters a lot for an evaluation agent. If the model has to translate before it can reason, something always gets lost. Mistral doesn't have to.
Qwen3 is a mix-of-experts model, meaning it uses an internal routing system to direct each query to specialized sub-networks rather than running the whole thing. That makes it faster than a dense model of similar size, and it's strong enough for deep analysis. The tradeoff: Dutch isn't a native language, so it works primarily in English.
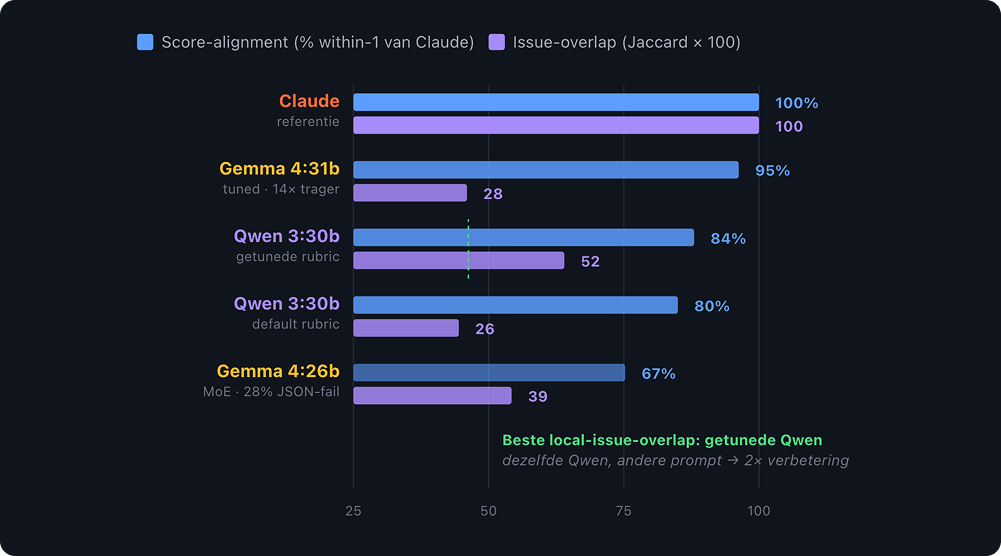
Gemma (Google's model) was tested and rejected. It scored well on alignment with the cloud benchmark, but it was noticeably slower; a consequence of being a dense architecture versus mix-of-experts. Tim also tried Gemma's own mix-of-experts variant, but it introduced new issues and wasn't significantly faster. Model dropped.
One deliberate design choice: Mistral and Qwen3 come from different organizations. That's intentional. Using two models from the same family means you risk inheriting shared biases in how they were trained. Different families, better cross-check.
The finding that surprised everyone
Rubric tuning had more impact than model choice.
How you write the evaluation prompt, the instructions that tell the model what to look for and how to score, matters more than which model you're running it through. After tuning the rubric, Qwen3's issue overlap score (how well it identified the same problems as the cloud benchmark) roughly doubled. Same model, better prompt.
That's worth sitting with. A lot of energy goes into picking the "best" model. The instructions you give it often deserve at least as much attention. 👀
What this means beyond Nimble's stack
The broader takeaway isn't about local models versus cloud. It's about task routing.
Not every step in an AI workflow needs a frontier model. Repetitive, structured tasks - like scoring a conversation against a fixed rubric - are well within what smaller open-source models can handle. Sending all of them to a cloud API is like hiring a specialist surgeon to take your temperature. Overkill.
The question isn't which model wins. It's which model fits which role best, and when.
For now, everything runs on Tim's laptop. Scaling this to a studio-wide setup is a different challenge, one that brings server infrastructure back into the picture, and with it, real costs again. That conversation is ongoing.
But as a proof of concept, the results are hard to argue with: 70% cost reduction, quality that holds up, and a system that knows when it needs to ask for help.